Encoding

Daten im Speicher
Section titled “Daten im Speicher”- Daten im Speicher können nur durch eine Reihe von Bits repräsentiert werden.
- Beim Einlesen der Daten müssen diese Daten interpretiert werden.

Textrepräsentation
Section titled “Textrepräsentation”- Damit wir eine Binärzeichenfolge als Text erkennen können, muss festgelegt werden, welche Abfolge von Bits welche Buchstaben bzw. Zeichen repräsentieren.
- Wir brauchen also eine Zuordnung zwischen Bitfolgen und Zeichen.

- Eine einfache (und schon etwas ältere) Möglichkeit der Binärfolgeninterpretation ist ASCII.
- Es steht für American Standard Code for Information Interchange
- ASCII enthält 128 Zeichen der englischen Sprache, sowie Steuer- und Sonderzeichen
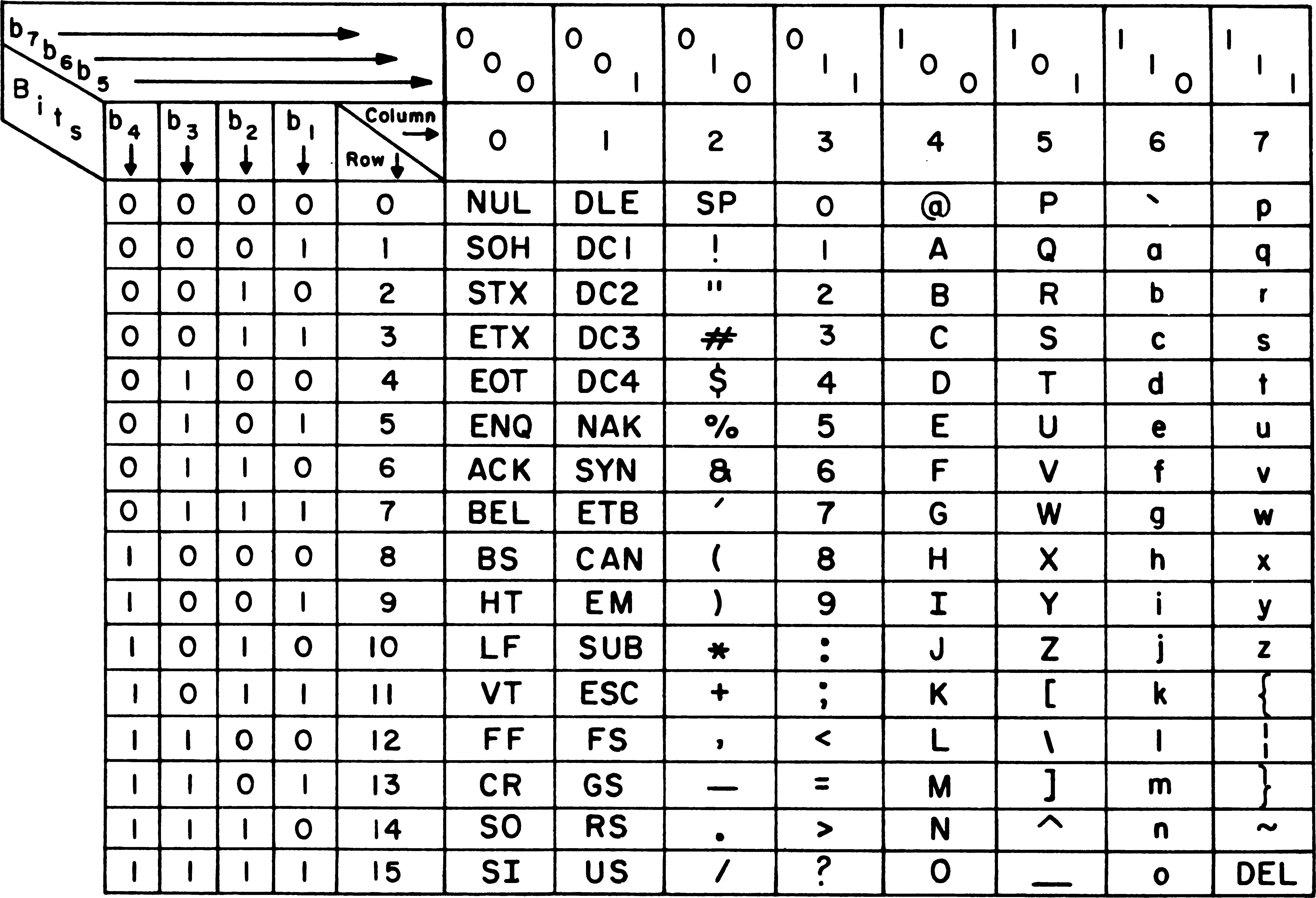
ASCII (2)
Section titled “ASCII (2)”- Die ASCII Tabelle enthält 128 unterschiedliche Zeichen.
- Ein einzelnes Zeichen kann durch eine Kombination aus 7 Bit dargestellt werden.
- Früher wurde das achte Bit als Kontrollbit verwendet um zu überprüfen ob ein gültiges Zeichen gespeichert wurde.
- Even Parity: Die Gesamtzahl der Einser muss gerade sein.
- Odd Parity: Die Gesamtzahl der Einser muss ungerade sein.
ASCII (3)
Section titled “ASCII (3)”- ASCII ist auf die englische Sprache ausgelegt. Es kommen zum Beispiel keine Umlaute vor.
- Es kommen folgende Zeichenarten vor:
- Großbuchstaben (A, B, C, …)
- Kleinbuchstaben (a, b, c, …)
- Sonderzeichen (!, #, $, …)
- Nicht darstellbare Zeichen (CR, LF, …)
Nicht darstellbare Zeichen
Section titled “Nicht darstellbare Zeichen”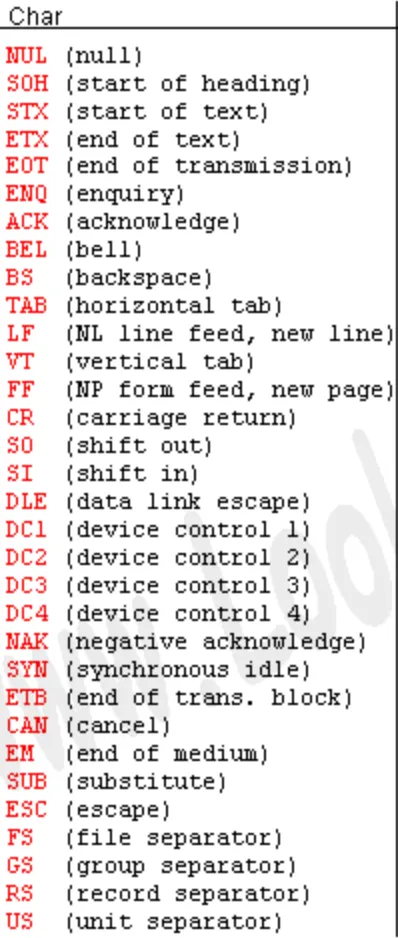
Nicht darstellbare Zeichen (2)
Section titled “Nicht darstellbare Zeichen (2)”- Sie werden auch Steuerzeichen genannt.
- Sie werden nicht auf dem Bildschirm ausgegeben.
- Sie sind dafür gedacht bestimmten Geräten (zB Drucker, Bildschirm) Anweisungen zu senden.
- Außerdem werden zB Zeilenumbrüche oder Einrückungen (Tab) mit diesen Zeichen dargestellt.
Windows vs. Unix
Section titled “Windows vs. Unix”-
Bis zum heutigen Tag werden in Windows und Unix-basierten Betriebsystemen Zeilenumbrüche unterschiedlich kodiert.
-
Windows: CR LF
-
Unix: LF
Dateiendungen
Section titled “Dateiendungen”Um zu Erkennen welche Daten in einer Datei auf dem Rechner gespeichert sind, werden (unter anderem) Dateiendungen verwendet.
- .doc .docx
- .txt .js
- .jpeg .png
- .exe
Dateiendungen helfen dem Betriebsystem zu erkennen, um welche Art von Datei es sich handelt, damit das richtige Programm dafür ausgewählt werden kann.
Magic Bytes
Section titled “Magic Bytes”Viele Dateien haben zu Beginn der Datei eine spezielle Abfolge von Bytes, die (zusätzlich zur Dateiendung) kennzeichnen um welchen Inhalt es sich handelt.
Magic Bytes (3)
Section titled “Magic Bytes (3)”Textdatein (.txt) können unterschiedliche Encodings verwenden, die durch die Magic Bytes gekennzeichnet werden.
| Magic Bytes | Beschreibung |
|---|---|
EF BB BF | UTF-8 BOM |
FF FE | UTF-16LE |
FE FF | UTF-16BE |
FF FE 00 00 | UTF-32LE |
00 00 FE FF | UTF-32BE |
Wenn keine Magic Bytes angegeben sind wird meist UTF-8 angenommen.
Endianness
Section titled “Endianness”Wenn mehr als ein Byte zur Darstellung eines Zeichens verwendet wird (zB UTF-16), müssen wir entscheiden in welcher Reihenfolge die Bytes, die zur Darstellung eines Zeichens verwendet werden vorkommen.
Beispiel: 0x1234 soll gespeichert werden:
| Byte Index | 0 | 1 |
|---|---|---|
| Big-Endian | 12 | 34 |
| Little-Endian | 34 | 12 |
- Big Endian: Das wichtigste (most significant) Byte wird an der kleinsten Speicheradresse gespeichert (=vor den anderen). Also das Zeichen endet an der größeren Adresse (-> Big Endian)
- Little Endian: Umgekehrt
BOM (Byte Order Mark)
Section titled “BOM (Byte Order Mark)”- Die Zeichenfolge
FE FFin Magic Bytes wird auch Byte Order Mark genannt, da sie angibt in welcher Reihenfolge (Little Endian / Big Endian) die Zeichen kodiert sind. FF FEsteht für Little EndianFE FFsteht für Big Endian
Die Angabe einer BOM ist optional und wird von vielen Programmen nicht verwendet und auch nicht erwartet. Standardmäßig wird Big Endian angenommen.
Erweiterungen zu ASCII
Section titled “Erweiterungen zu ASCII”- ASCII in Reinform kommt heute kaum noch vor.
- Viele Sprachen haben Sonderzeichen, die in der englischen Sprache nicht vorkommen.
- Anforderung, neben Buchstaben auch andere Zeichen darzustellen steigt (zB Emojis)
- Heute gebräuchliche Encodings sind unter anderem UTF-8, UTF-16 und ISO-8859-1
- Steht für: Unicode Transformation Format - 8 bit
- Mit UTF-8 wurde eine Erweiterung zu ASCII geschaffen die heute weit verbreitet ist.
- Bei UTF-8 sind Zeichen variabel zwischen einem und vier Bytes lang.
- Ein Zeichen wird auch Code Point genannt.
- Die ersten 128 Code Points sind deckungsgleich mit dem ASCII Zeichensatz.
UTF-8 Variable Länge
Section titled “UTF-8 Variable Länge”| First code point | Last code point | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
|---|---|---|---|---|---|
| 0x0 | 0x7F | 0xxxxxxx | |||
| 0x80 | 0x07FF | 110xxxxx | 10xxxxxx | ||
| 0x0800 | 0xFFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |
| 0x10000 | 0x10FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
Die x in der Tabelle werden mit dem Wert des jeweiligen Code Point ersetzt. Anhand des ersten Bytes kann erkannt werden wie viele Byte der Code Point braucht.
UTF-8 Enthaltene Zeichen
Section titled “UTF-8 Enthaltene Zeichen”- Die ersten 128 Code Points brauchen ein Zeichen. Sie entsprechen dem ASCII Zeichensatz.
- Die nächsten 1.920 Code Points brauchen zwei Bytes und enthalten nahezu alle Zeichen der Latein-basierten Sprachen und Zeichensätze, inklusive Umlaute, Accents, Griechisch, Kyrillisch, Koptisch, Armenisch, Arabisch, Syrisch, phonetisches Alphabet, …
- Drei Bytes werden benötigt für die verbleibenden 61.440 Code Points der BMP (Basic Multilingual Plane), u.a. Chinesisch, Japanisch und Koreanisch.
- Vier Bytes werden verwendet für die 1.048.576 Code Points der anderen Bereiche, inklusive Emojis, weniger gebräuchliche chinesische Zeichen, historische Schriften und mathematische Symbole.